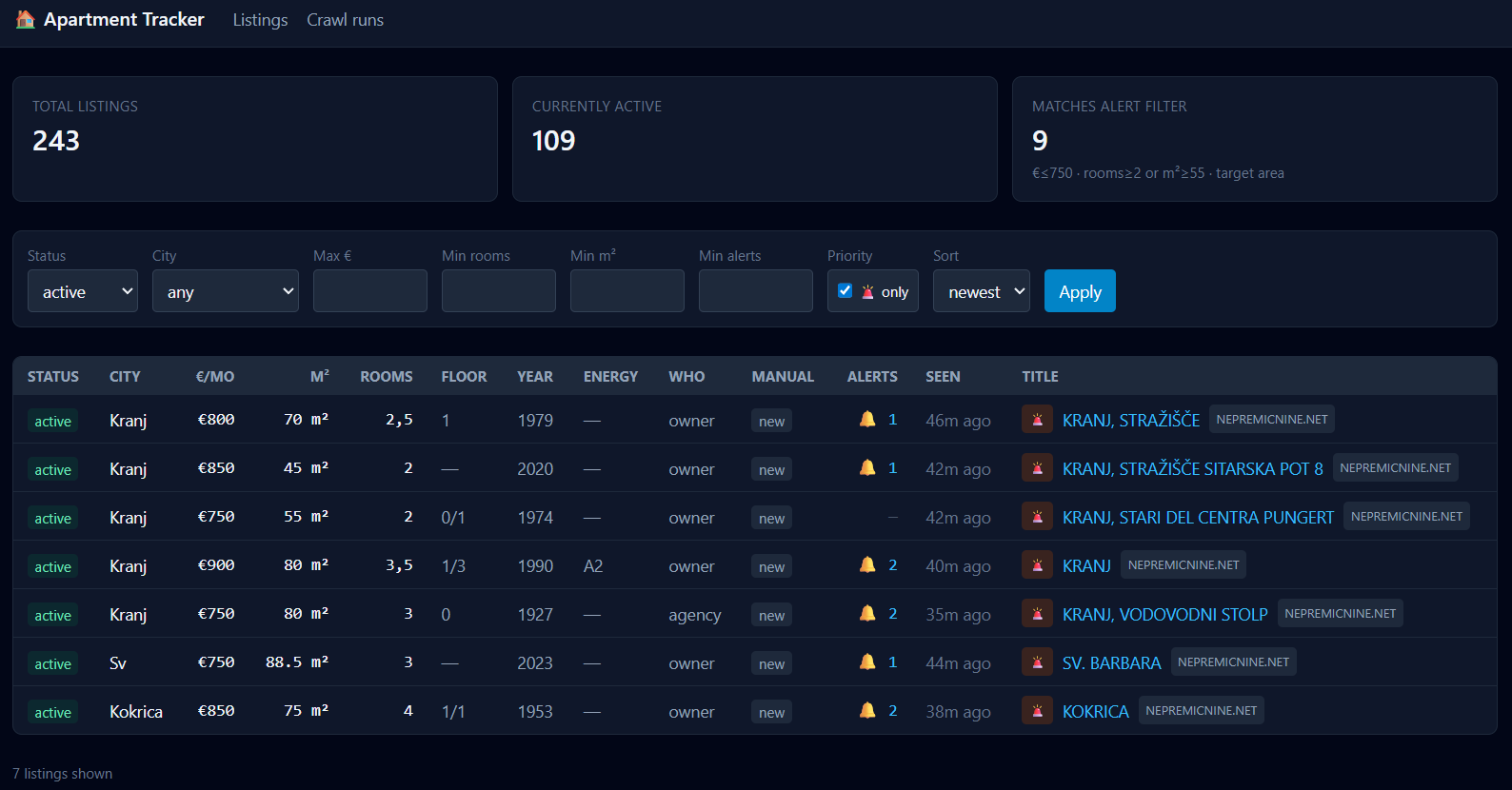
Why I Built It
Our landlord in Ljubljana decided to sell the flat. He gave us until the end of June 2026 so our teenage son could finish the school year. That left a single search window: a few months to find a long-term rental in Kranj, vacate one apartment, and move into another. Real deadline. Real consequences. Real budget — about €850/month all-in for rent plus utilities, three people, fiber-capable address required because I work remote.
Slovenian rental portals have no usable alerts, no cross-portal dedup, no notion of "score this against a personal rubric." The portal pages are in Slovene; the family member doing most of the search reads Russian more comfortably. Refreshing nepremicnine.net by hand twice a day, copy-pasting promising listings into a spreadsheet, then translating the relevant bits — that was the manual baseline, and it scaled to about three days before it broke.
So I built the system the search needed. It is now production on a Contabo VPS, has been running since April, and has been the spine of every viewing the family has scheduled.
The Two-Agent Split
The novel thing in this stack — the thing that made me want to write it up — is that two Claude CLI agents run as part of the production runtime, not as an IDE tool I use to write code.
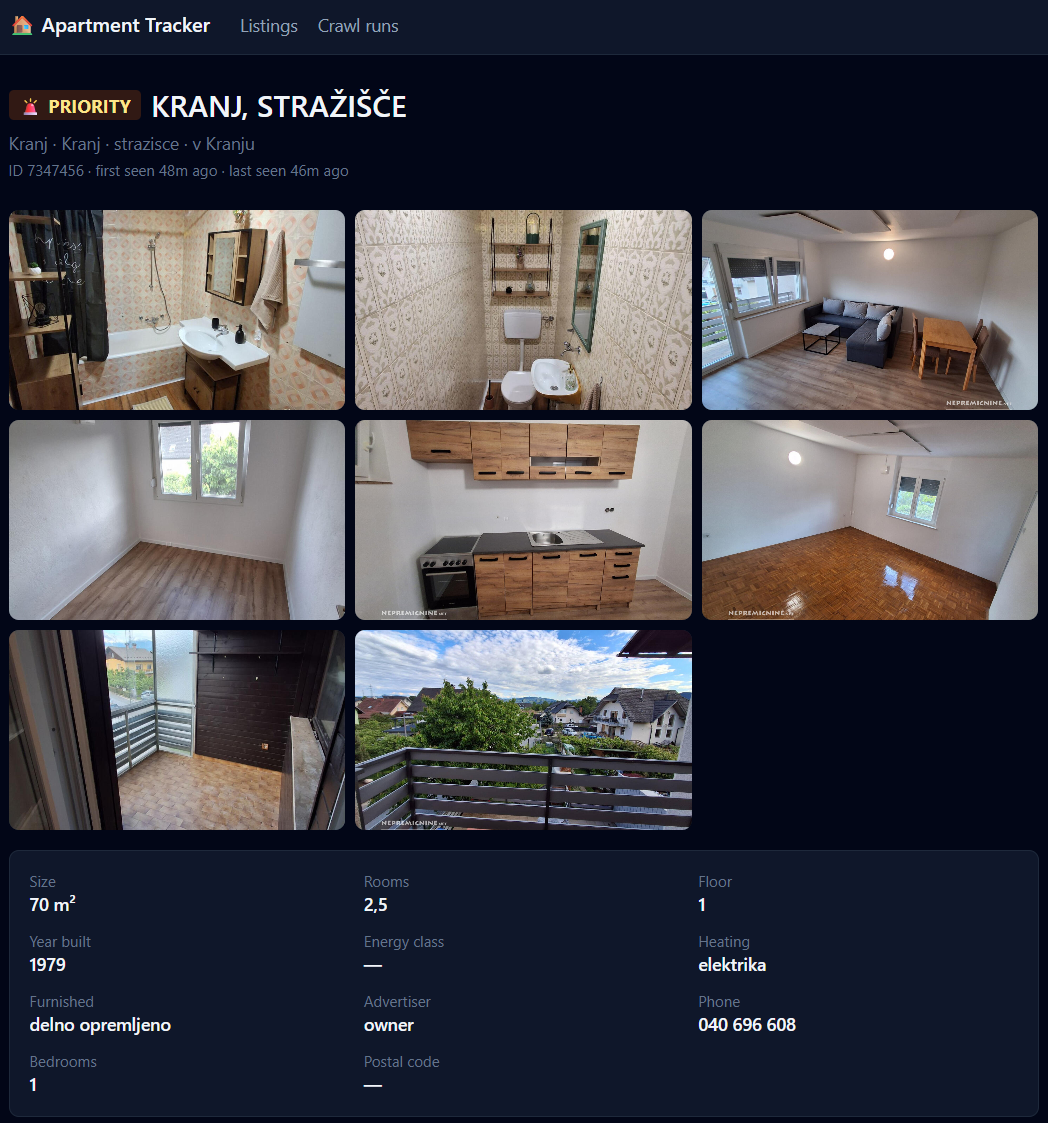
- The priority-scorer judges every fresh listing on a 0–10 scale across six axes: location, budget, size/layout, condition, advertiser, timing. If the score crosses a threshold (currently 7.0), it auto-flips an
is_priorityboolean on the listing. - The listing-analyzer authors the Russian-language Telegram alert: a full current-state snapshot — price, size, rooms, floor, year, advertiser, distance from Kranj — with the listing's first image as a photo caption and the URL inline.
Both agents shell out to the claude CLI bound to a Max-plan OAuth session that's logged in on the VPS. There is no ANTHROPIC_API_KEY set anywhere; the code defensively strips it from the child environment so the CLI doesn't accidentally prefer it. JSON output mode, no tools allowed, system prompt fed from a SKILL.md file. The Node.js code validates every response against a zod schema, persists every call to a cache table keyed by SHA1 of the input JSON, and respects a daily USD budget cap. If the agent fails — malformed JSON, schema mismatch, circuit-breaker open after consecutive failures — the listing proceeds without the priority flag and the alert still goes out using a legacy formatter.
The split mattered. Mixing scoring and copy-authoring into one prompt produced worse scores and worse prose. Separating them let me calibrate the scorer against a deliberately narrow rubric (more on the golden-template trick in a moment) and let the analyzer focus on tone — short Russian sentences, no emoji except an event header, "Почему приоритет:" verdict line for flagged listings.
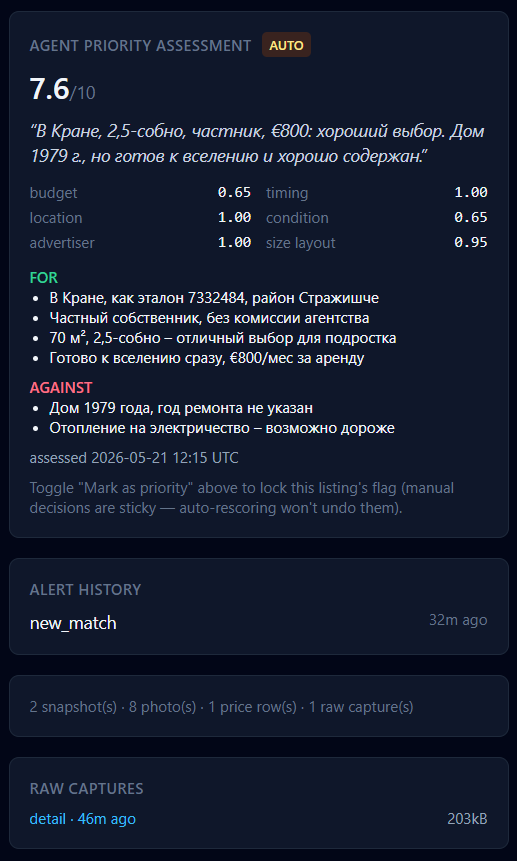
The screenshot above is a real assessment. The agent gave this listing 7.6/10. The FOR and AGAINST reasons are in Russian — the agent writes those directly, in short concrete phrases tied to the listing data, not generic praise. The AUTO badge means the priority flag was set by the scorer, not by me. The note at the bottom — "manual decisions are sticky — auto-rescoring won't undo them" — is the most important rule of the whole system, and I'll come back to it.
The Golden-Template Trick
The scorer's calibration anchor is a single, specific listing: a Kranj apartment our family had already seen, scored, and almost rented before it got pulled off the market. 65 m², €750 rent, modern build, fiber explicitly mentioned, ready to move in by 1 June 2026, private owner. We knew it was good. We knew exactly how good.
Instead of trying to teach the agent "what makes a good listing for a Slovenian family of three" in the abstract, the system prompt names this exact listing by ID and says: this one scores ~9.8 out of 10. Everything else is scored by how close it is to this anchor across six named axes. There's also a calibration table — "if location is good but advertiser is an agency and the building is 1990s unrenovated, that's around 7.0" — that gives the agent concrete reference points.
This worked better than every abstract rubric I tried. Concrete anchoring beats prompt-engineered abstraction.
Raw HTML, Gzipped, Forever
Every list-page and every detail-page fetch persists its gzipped HTML bytes into a raw_pages table in Postgres. Bytea column, ~5× compression, deduped by (source_slug, url, content_hash) so the same byte-identical page only lands once even if it gets fetched a thousand times.
This is an ELT layer. The parsers can be re-run offline against stored bytes whenever I bump a parser version. The fetch and the parse are decoupled.
That decision paid for itself the first time I had to fix a parser bug. A new field appeared in nepremicnine.net detail pages — energy class as a separate field rather than embedded in the heating string. I bumped the adapter's parserVersion constant in the same commit that updated parseDetail. Next scraper tick, the reparse pass picked up every existing row where the stored parser_version was lower than the new value, re-ran the parser against the gzipped HTML, applied the result, bumped the row. Hundreds of historical listings got the new field, no refetch, no portal traffic, no proxy load.
The reparse loop uses FOR UPDATE SKIP LOCKED so overlapping crawl ticks don't double-process the same row. A row that fails to parse three times gets its parser_version advanced anyway, with the error logged in a notes column, so we never spin on a permanent failure — a future version bump retries it.
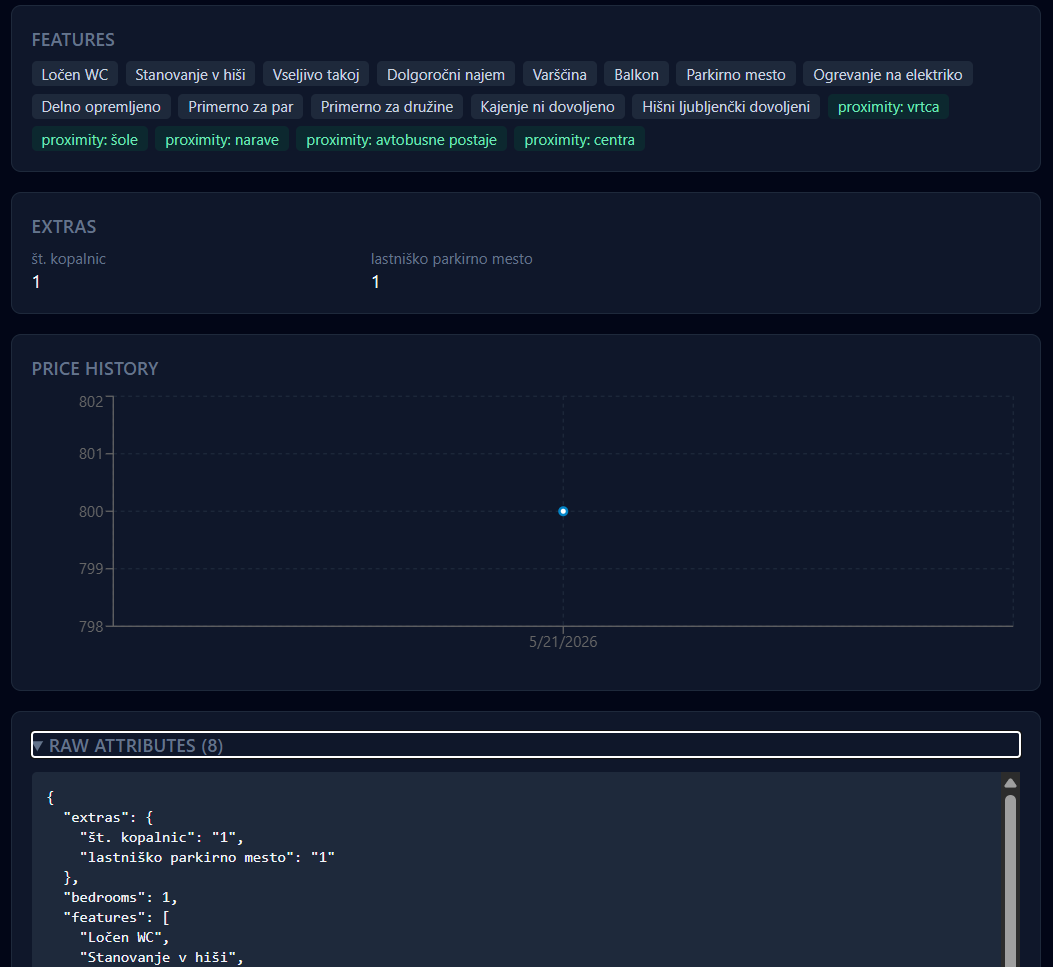
That raw-attributes JSON block at the bottom of the detail page exists for the same reason as the gzipped HTML: when a parser misses something, the answer is one click away.
Multi-Source Adapters and the Cloudflare Detour
Slovenia has more than one rental portal. The stack supports two in production (nepremicnine.net, svet24.si) and two more scaffolded behind environment flags (nepogl, bolha.com). The rest of the pipeline — fetch, upsert, score, alert — is source-agnostic; each adapter exports a small interface (listPageUrl, parseListPage, parseDetail, extractSourceListingId, fetchMode, parserVersion) and the runner looks adapters up by slug.
The interesting bit is fetchMode. Some portals serve plain HTML to the VPS IP. Others — nepremicnine.net is the loud one — block the Contabo IP at Cloudflare. For those, the adapter declares fetchMode: "browser", which routes the request through Playwright + a custom HTTP proxy. The proxy chain looks like this:
[scraper on VPS] --NetBird mesh--> [tinyproxy on home Orange Pi 5] --residential ISP--> nepremicnine.net
The home Orange Pi runs a tinyproxy bound only to the mesh interface, filter-whitelisted to the target hostname. That's it — a residential-IP egress for the scraper, joined to the VPS over a private NetBird mesh, with no direct exposure of either machine to the public internet. The home machine is not a server in any normal sense; it's a Pi running a 30-line tinyproxy config.
Same database, same parser, same agents. The only thing the fetch-mode flag changes is which HTTP path the bytes come in through.
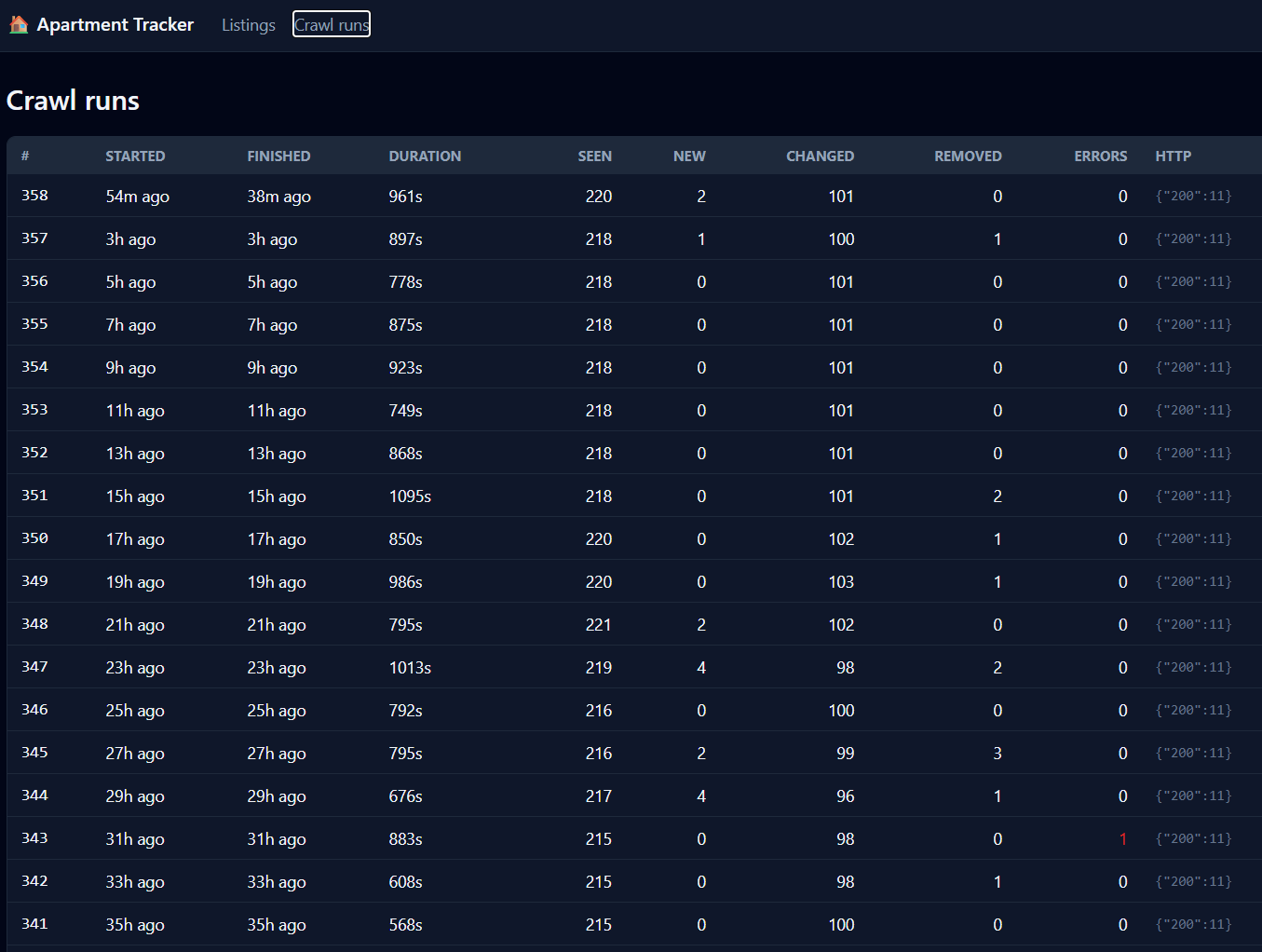
The crawl-runs table is the observability layer. Every tick writes one row: how long it ran, how many listings it saw, how many it inserted, how many it updated, how many it marked removed, how many fetch errors, and a JSON histogram of the HTTP status codes it actually got. When the Cloudflare block first hit, this table was where I saw it — a sudden stripe of {"403": 11} rows. Two weeks later, after the NetBird proxy chain was in place, it went back to clean {"200": 11}.
Sticky-Manual Priority — The One Rule That Matters
Here's the rule that took longest to get right and matters most:
Manual override is sticky. Auto never overwrites a manual decision, in either direction.
The dashboard has a Priority toggle on every listing. When a human flips it — on or off — the system records the change with priority_source = 'manual'. The auto-scorer reads that column first; if it's 'manual', the auto-update is a no-op. The agent still scores the listing (the assessment numerics still land in the database for the sidebar), but the flag itself doesn't move.
This matters because the agent will sometimes be wrong. It'll flag a listing that, in the photos, is clearly a half-converted garage. Or it'll miss-rate a perfect listing because the description was sparse. The human needs to be able to say "I've decided about this one" and have that decision survive every subsequent re-score, including ones triggered by price drops or new data appearing on the listing.
The inverse is also true: if I've manually unflagged something, the agent re-scoring at 8.4 doesn't put the badge back. Once a human has made a call, the system stops second-guessing.
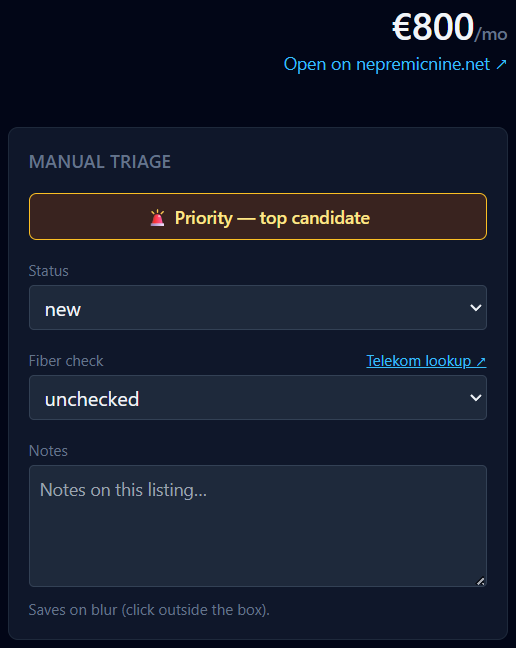
That sidebar is the entire surface the family uses for triage. Priority toggle, status (new / contacted / viewing scheduled / passed), fiber check with a deep link to the Telekom address-lookup tool, and a free-text notes field that auto-saves on blur. Every meaningful state lives here; everything else is information.
The Telegram Layer
Alerts go to a family Telegram supergroup. Three event types: new_match (listing first appears and passes the filter), price_change (any direction — drops AND rises, because a rise sometimes means the owner is testing the market), and delisted (status flipped to removed, either via a 404 or via "not seen in crawl for N ticks").
Each alert is a full current-state snapshot, not a diff. Price, size, rooms, floor, year built, advertiser type, distance from Kranj, listing's first image as a photo caption, direct URL. Russian-language. If the agent flagged the listing as priority, the standard event header gets replaced with 🚨 ПРИОРИТЕТ — НОВОЕ (or ЦЕНА СНИЖЕНА, ЦЕНА ПОВЫШЕНА, СНЯТО С АРЕНДЫ for the other event types), and a "Почему приоритет:" line gets injected right after the header carrying the scorer's one-line verdict.
The whole alert flow is idempotent. There's an alerts_sent table keyed by listing+event-type, so the scraper restarting doesn't re-fire alerts the family has already seen. There's a listing_analyses cache keyed by SHA1 of the canonical input JSON to the analyzer, so re-running the agent on identical input is free. A --force CLI flag bypasses both, which is what I use when I'm iterating on the SKILL.md prompt and want to re-fire on a known listing.
What This Taught Me About Agents-In-Production
The whole stack is, by line count, mostly not AI. It's a TypeScript scraper, a Drizzle schema, a Next.js dashboard, a node-cron loop, four systemd units (postgres / scraper / web / backup). The agents are a small, well-bounded subsystem inside that. They get fed structured input, they produce strict JSON output, they have a cache layer in front of them, they have a circuit breaker behind them, and they have a manual override that always wins.
That's the pattern I'd recommend for anyone running Claude agents in production today:
- Bound the agent's job narrowly. The scorer doesn't write the alert. The analyzer doesn't decide priority. Each one does one thing.
- Anchor calibration to a concrete example, not abstract rubrics. Naming the golden-template listing by ID worked better than any "what makes a good listing" prose I tried.
- Cache by hash of the input. Re-running an agent on identical input should be free. This also makes prompt iteration cheap — I can re-fire on a known listing with one flag.
- Strict JSON schemas with zod validation. Free-form LLM output is the enemy of production. Define the shape, validate every response, treat schema failure the same as any other API error.
- Daily budget caps. The agent that runs every two hours over hundreds of listings can run away. Cap it.
- Circuit breakers. Three consecutive failures in a single crawl tick → fall back to the legacy formatter for the rest of the tick. Resets next tick.
- Sticky-manual override. The human always wins. Always. In either direction.
This article isn't about how fast you can ship with Claude Code in the IDE. It's about what you build when the agent isn't a coding assistant anymore — when it's a small, defensible component of a system that runs without you.
The family is still mid-search as of writing. The tracker has fired several dozen priority alerts, surfaced three serious candidates, and made the difference between "we are casually browsing" and "we have a system." Whatever apartment we end up signing the lease on, the agent will probably have flagged it first.