Why This Is the Flagship
Every other AI-assisted project in this portfolio is a smaller, cleaner version of something. A site clone that lands in hours. A scraper that ships in a few weeks. A LinkedIn pipeline that exists because manual posting hit the wall.
This one is different. The Automated Trading System has been in continuous development since November 2025, trades real money against a live exchange 24/7, and exists specifically to answer one question with as much fidelity as possible: does AI-assisted development scale when the system has to be right, not just impressive?
The short answer is yes — but the long answer is what's interesting. It scales not because Claude Code writes better code than I would alone (sometimes it does, sometimes it doesn't), but because the discipline that makes AI-collaboration work at this scale forces every other engineering practice into a more rigorous shape. Plans become artifacts before they become code. Documentation becomes something the agent fleet maintains. Anti-patterns from real production incidents become permanent guardrails. The system gets more coherent as it grows, not less.
This article is the centerpiece of the portfolio because the patterns it surfaces — plan-first development, self-maintaining docs, an agent fleet with named roles, anti-patterns captured as committed warnings, local timers for deferred Claude work — are what I lift into every other project I build. The trading is the proof point. The discipline is the message.
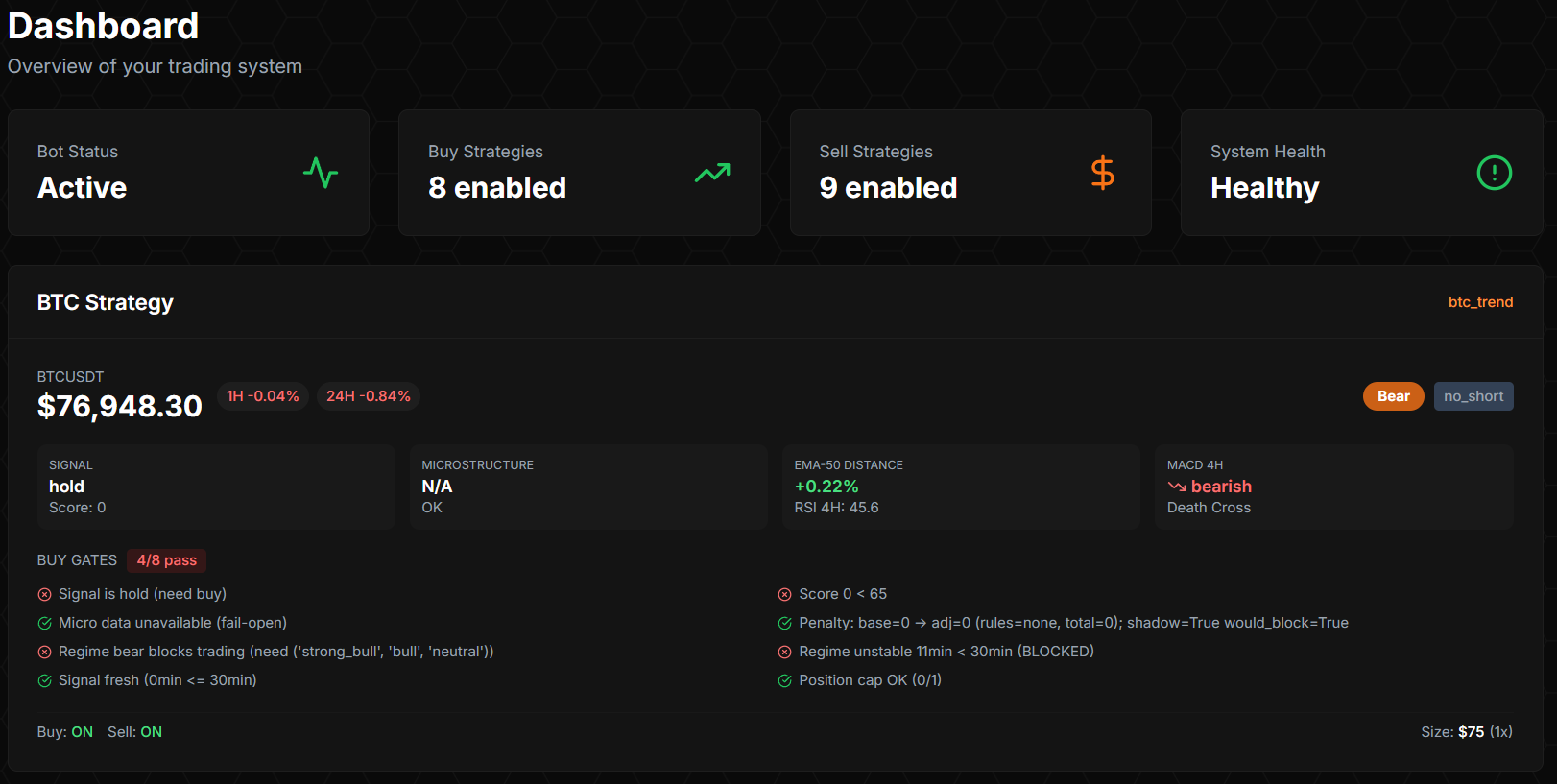
The System at a Glance
Hybrid microservices on a dedicated Contabo Debian 13 server. Python/FastAPI runs analytics, OHLCV data collection across five timeframes (15m, 1h, 4h, 1d, 1w), watchlist scoring, microstructure signals from ByBit (open interest, funding rates, long/short ratio, taker volume), and backtesting. Node.js/TypeScript runs the trading bot with ByBit WebSocket execution, order lifecycle management, trailing TP/SL, and risk gates. React/Vite dashboard. PostgreSQL 16 with 42 tables and 134 migrations. Redis cache. Isolated Docker networks for zero-trust topology between services. Nginx Proxy Manager with Let's Encrypt SSL.
Eleven strategies in total — four long (spot buys: growth-potential, momentum, mean-reversion, BTC trend hybrid), four short (linear perpetuals at 1× leverage: trend-breakdown, momentum-short, mean-reversion-short, BTC trend short), three specialty (range-fade long/short, BTC swing long-horizon). Every strategy has independently gated watchlist, buy, and sell switches. Every parameter — TP/SL percentages, trade amounts, rate limits, hold durations, cooldowns — lives in a single strategy_configurations table that's the source of truth. Config in the database, not in code.
That summary is the easy part. The interesting part is what makes a system at this scale maintainable when the primary developer is one person collaborating with Claude Code as the IDE.
The Plan-First Rule
The single most load-bearing line in this entire codebase isn't code. It's in CLAUDE.md:
You MUST call
EnterPlanModebefore making ANY code changes to files underservices/orfrontend/. This includes bug fixes, feature additions, refactors, and UI changes — no exceptions.
That rule is enforced by my own discipline, not by tooling. But the consequence of enforcing it is visible in the repo: 287 plan files committed to plans/, each timestamped, each named for what it does, each readable as a standalone artifact. A representative day produces 1–3 plans. A heavy day produces 6–8. None of them are throwaway.
The mechanics: enter plan mode, research with the knowledge-base query tool first (more on that in a moment) before exploring the codebase manually, present a concrete implementation plan, get approval, then run a slash command (/save-plan) that copies the approved plan verbatim into plans/<YYYY-MM-DD>_<HHMM>_<descriptive-name>.md before any code changes happen. The plan gets committed in the same PR as the implementation.
Why this matters at scale: the plan is the artifact a reviewer (future-me, or anyone collaborating with me) reads to understand a change. Not the diff. Not the commit message. The plan. It explains the alternatives considered, the tradeoffs evaluated, and the specific decisions made — all in language designed for a human reader, not a compiler. When a year-old change starts behaving unexpectedly, I read the plan from that day, not the code archaeology, because the plan tells me why the code looks the way it does.
This discipline is also what makes Claude Code at this scale viable. Without plans, every session starts from zero. With plans committed, every session can reload context by reading the relevant plan files. The plan is the persistence layer.
The Self-Maintaining Knowledge Base
The codebase has a thing called the ATS Knowledge Base: 151 markdown articles, one per module or subsystem, each documenting what that module does, how it's wired into the rest of the system, what its key invariants are, and where the gotchas live.
You'd expect that kind of documentation to rot. It doesn't, because agents maintain it.
There's a knowledge-base-agent registered in .claude/agents/. It owns the ats_kb_registry table in Postgres, which stores one row per source file (path, MD5 hash, current KB article path, version, status). When a source file changes, its MD5 drifts. A /update-knowledge-base slash command sweeps the registry, finds entries where the source-file MD5 no longer matches the recorded one, marks them stale, and rebuilds the affected articles by running the knowledge-base agent against the new source. The dashboard exposes a UI view of the KB — articles grouped by category (AGENTS, ANALYTICS, API-GATEWAY, FRONTEND, MODULES, OPERATIONS, PACKAGES, REPORTS, SKILLS, STRATEGIES, TRADING-BOT), with status counters: 151 active, 0 stale, 0 pending, 0 failed.
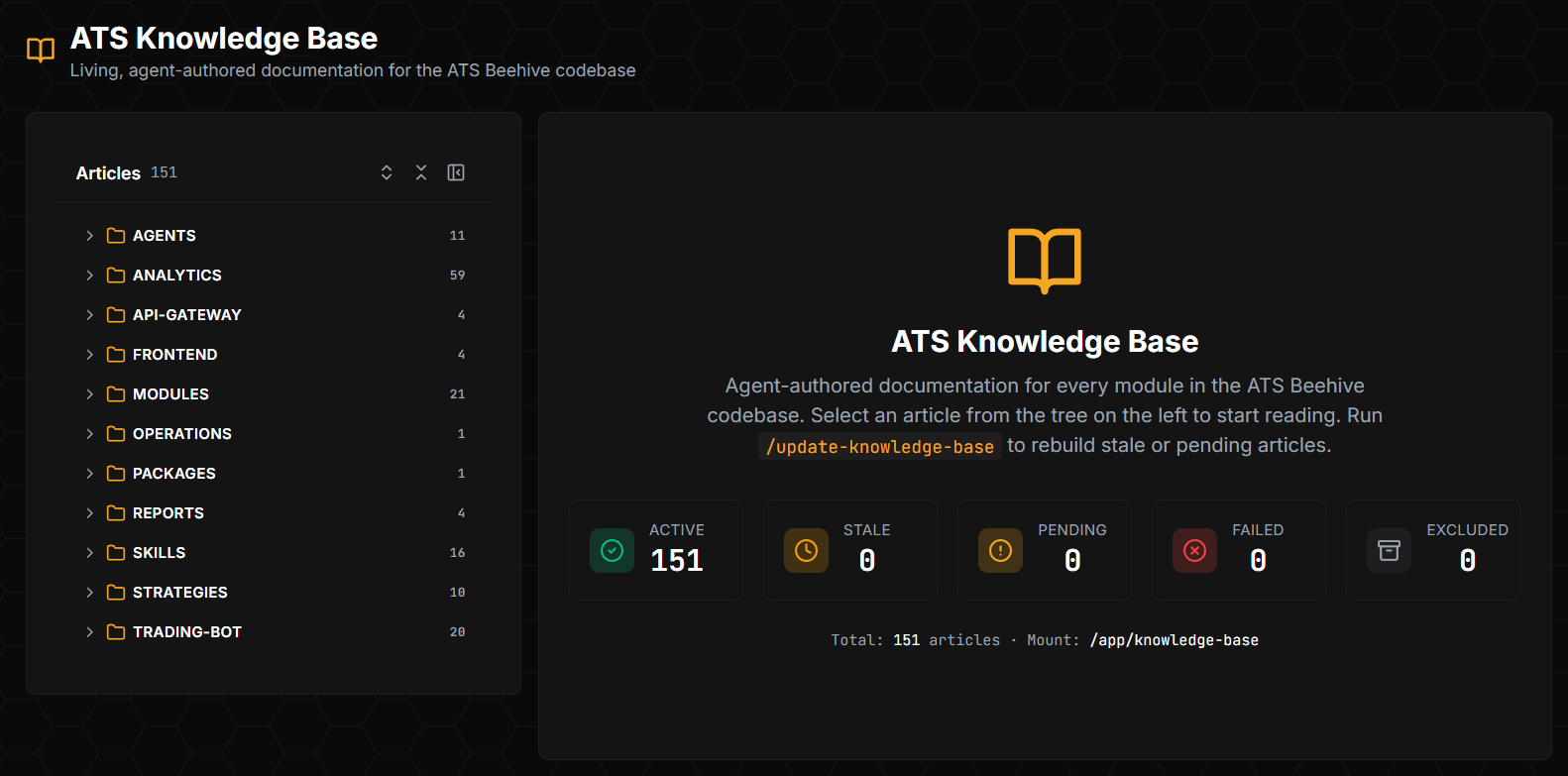
This solves the worst documentation failure mode: docs that lie because no one updated them when the code changed. The agent doesn't care about being thorough. It cares about being current.
Beyond the KB, there's a separate documentation search layer — qmd (quick markdown), a hybrid BM25 + vector search index over the project docs, plans, reports, and knowledge-base articles. It's available both as a CLI binary and as an MCP server. When I'm planning a change, the rule (also encoded in CLAUDE.md) is: query the knowledge base first, before exploring the codebase manually. The indexed docs give faster, more relevant results than recursive Grep through a microservices repo.
The Agent Fleet
There are 11 named agents living in .claude/agents/, each with a specific role:
ats-db-backup— runspg_dumpagainst the Postgres container, ships the dump todb_backups/with rotation.ats-health-check-agent— post-trade health checks, strategy adherence audits, system optimization.ats-live-monitor-agent— synthesizes audit reports from archived live-monitor JSONL state files.git-workflow-agent— commits, branches, and the/commitslash command's heavy lifting.github-issues-agent— issue management (list, create, close, comment, link, projects).investigate-agent— investigates a symbol's full trading lifecycle from order placement through close, including blocked-signal forensics.knowledge-base-agent— builds and refreshes KB articles by detecting source-file MD5 drift.ops-health-agent— deployment, troubleshooting, monitoring, the daily ops console.project-backup-archiver— full project backup to Google Drive.security-monitor— security audits and threat detection.trading-report-agent— weekly trading performance reports.
Each agent is a markdown file with a specific system prompt, a defined tool allowlist, and a clear job description. They're invoked through Claude Code's Task tool, not by me typing instructions. The naming convention is deliberate: <domain>-<verb>-agent reads as a function call.
The value isn't that the agents are smart on their own. It's that they encode role boundaries. When I'm investigating a bad trade, investigate-agent runs the same multi-step forensic process every time — read order_executions for the symbol, read position_evaluations for the auto-sell decisions, read system_events for the audit log, cross-reference with position_targets for the TP/SL history, produce a markdown report in reports/. I don't have to remember which tables to query. I run /investigate AVAXUSDT and the report lands.
The Slash-Command Cockpit
There are 16 slash commands in .claude/skills/, each one a short markdown file declaring "this is what I do, here's the prompt I run." The daily cockpit looks like this:
/ats-health-check— post-trade health check + adherence audit./24-h-trade-analysis— pick 5 representative trades from the last 24h (2 worst, 2 best, 1 middle), run/investigateon each in parallel, produce 5 forensic reports + a summary index./commit [hint]— commits and pushes viagit-workflow-agent./investigate <SYMBOL> [date filter]— investigate one asset's full trading lifecycle./watchlist-healthcheck— watchlist capture effectiveness vs the top 7-day market gainers./weekly-report— comprehensive weekly trading report./save-plan— copy approved plan from Claude Code's plan dir to the repo'splans/./check-issues,/create-issue,/close-issue,/comment-issue,/link-commits— GitHub issue lifecycle./close-session— end-of-session workflow: commit, branch sync, DB backup, project backup, restart, health check./update-knowledge-base— rebuild stale KB articles./start-ats-live-monitoring,/stop-ats-live-monitoring-save-report— start/stop a 30-second-polling background daemon (nohup) that audits live ATS operation against expected behavior, writing JSONL state. Pairs into a synthesized audit report on stop.
That last pair is the most interesting one. A live-monitor daemon, started by a slash command, polling 24/7 in the background, writing structured state that an agent later turns into a forensic report. It survives chat-session exit (it's nohup'd) but not a server reboot — by design, because if the server reboots I want to know about it from somewhere else first.
Local Timers + Cron, Not the Harness's /schedule
Here's the rule I learned the expensive way and committed to CLAUDE.md so I never forget:
Use local systemd timers / crontab for deferred and recurring tasks — NOT the
/scheduleor/loopskills. The harness's/scheduleskill launches remote agents that cannot reach this server's PostgreSQL container, Docker socket, repo tree, or themcp__postgres__queryserver, so any database-aware follow-up scheduled that way will silently no-op./looponly works while a Claude Code session is alive. On this server, deferred work must run locally so it survives reboots and inherits the full env (Docker, MCP servers, gh, qmd).
So all deferred ATS follow-ups — post-soak reviews, Phase-2 enable checks, periodic health audits, retrospectives — run as crontab entries or systemd timers that exec claude --print against a slash command or a checked-in prompt file. Pattern A (recurring) lives in /etc/crontab:
0 6 * * * cd /srv/ats-beehive && claude --print --dangerously-skip-permissions "/watchlist-healthcheck" >> logs/cron/watchlist-healthcheck.log 2>&1
0 7 * * * cd /srv/ats-beehive && claude --print --dangerously-skip-permissions "/ats-health-check" >> logs/cron/ats-health-check.log 2>&1
Pattern B (one-shot deferred — "fire this prompt once, three days from now") uses a systemd timer + oneshot service + a wrapper script in .claude-cron/. The wrapper script and the prompt file are both committed to the repo for audit; the systemd unit lives in /etc/systemd/system/ but its source-of-truth content gets mirrored into the matching plan file so it can be re-installed after a server rebuild. Persistent=true on the timer means a missed firing (e.g., if the server was offline) runs at next boot. Reboot-safe.
The pattern that took me time to internalize: deferred Claude work should usually be read-only investigation + report + GitHub comment. Code or config mutation should land in a chat-driven session, not in a headless cron run, until the operation has been validated. This sounds restrictive; in practice it's just right.
Anti-Patterns Captured as Permanent Docs
The single most important thing I've learned about running an LLM-collaborated codebase is this: forensic context from real production incidents has to land somewhere the next session can find it, or you re-discover the same bugs in slightly different forms forever.
The mechanism I use is a section in CLAUDE.md for each anti-pattern, with the incident date, the bad pattern, the right pattern, and the impact. Two examples that earned their permanent home in the docs:
The P&L double-count. A naïve SUM(usd_value) FROM wallet_balances once reported the portfolio at +20.6% while the authoritative portfolio_hourly_snapshots row showed -8.18% — a $200 gap that misled an entire day's fix-slate analysis. The wallet-balances sum double-counts duplicate USDT rows from different account legs, doesn't include LIFO realized-P&L attribution, and reflects raw wallet state that lags the analytics snapshot. The rule, now hardcoded in docs: all agents anchor portfolio state to two specific Analytics endpoints. Never derive ad-hoc.
The running-cumulative trap. A slate draft once summed hourly net_pnl_daily values and claimed +$24.51 last 4 days / +$6/day exceeding target. The correct DISTINCT-ON daily query showed the real value: +$2.22 last 4 days / +$0.56/day — a ~10× multi-count error that flipped the slate's framing from "exceeding target" to "break-even." The column is a running-cumulative-since-00:00-UTC field, not a per-hour delta. Summing hourly rows multi-counts.
Both of these are now permanent warnings in CLAUDE.md with the date, the symptom, the wrong query, and the right query side-by-side. When a new session asks Claude to compute weekly P&L, the warning is already in context. The bug doesn't re-occur — not because Claude is smart, but because the discipline of capturing every nontrivial forensic lesson as a committed warning means the agent fleet inherits institutional memory.
Strategies, Gates, and the Watchlist
Eleven strategies, each independently switchable across three gates: watchlist (does this strategy contribute its scoring signal to the watchlist?), buy (can this strategy place new entries?), sell (can this strategy close positions?). A strategy can be watchlist-only (scoring without trading), buy-disabled (no new entries but existing positions get managed), or fully active.
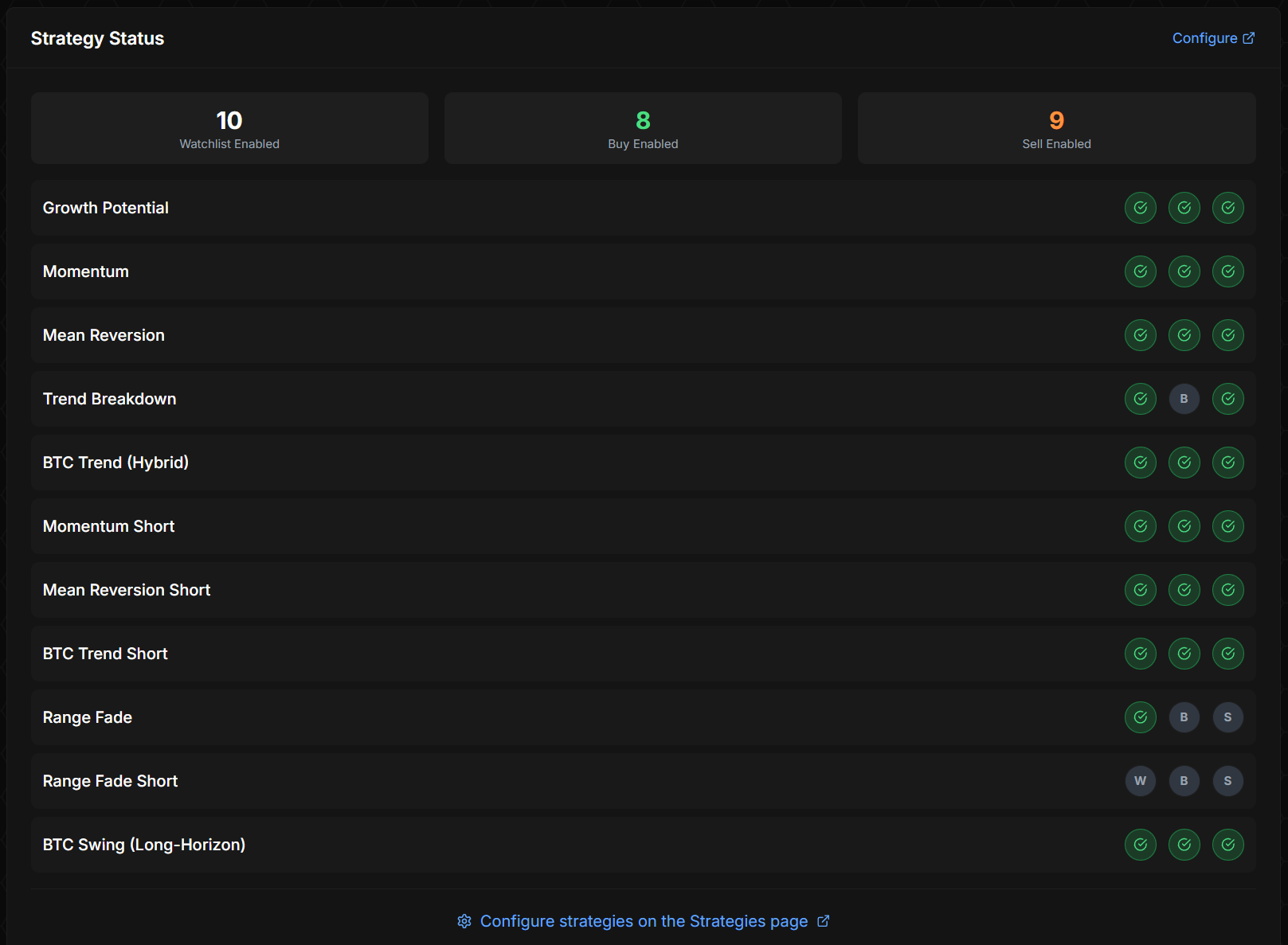
The independent gates matter because enabling a strategy is a decision in two phases: first you turn on its watchlist scoring so you can observe what it would have done over a soak period, then you turn on its buy gate. This staged rollout is what makes adding a new strategy safe — you watch its hypothetical signals for days or weeks before any real capital touches it.
That's the meta-pattern: every meaningful change to a live trading system gets a soak period first. The agent fleet helps enforce this — the /start-ats-live-monitoring daemon writes JSONL state of what each enabled strategy is doing vs. expected, and /stop-ats-live-monitoring-save-report synthesizes the audit when the soak period ends.
BTC Regime Awareness
The watchlist and several strategies are gated by BTC market regime — strong_bull, bull, neutral, bear, strong_bear. Long strategies pause in confirmed bear regimes. Short strategies pause in confirmed bull regimes. The BTC trend strategies themselves are regime-adaptive: btc_trend runs Pullback Buyer logic in bull regimes and Breakout Catcher logic in neutral, with no entries in bear; btc_trend_short runs bear_pullback_short (EMA-50 rejections) and breakdown_short (volatility squeeze resolutions) only in confirmed bear regimes, with funding cost as a hard gate.
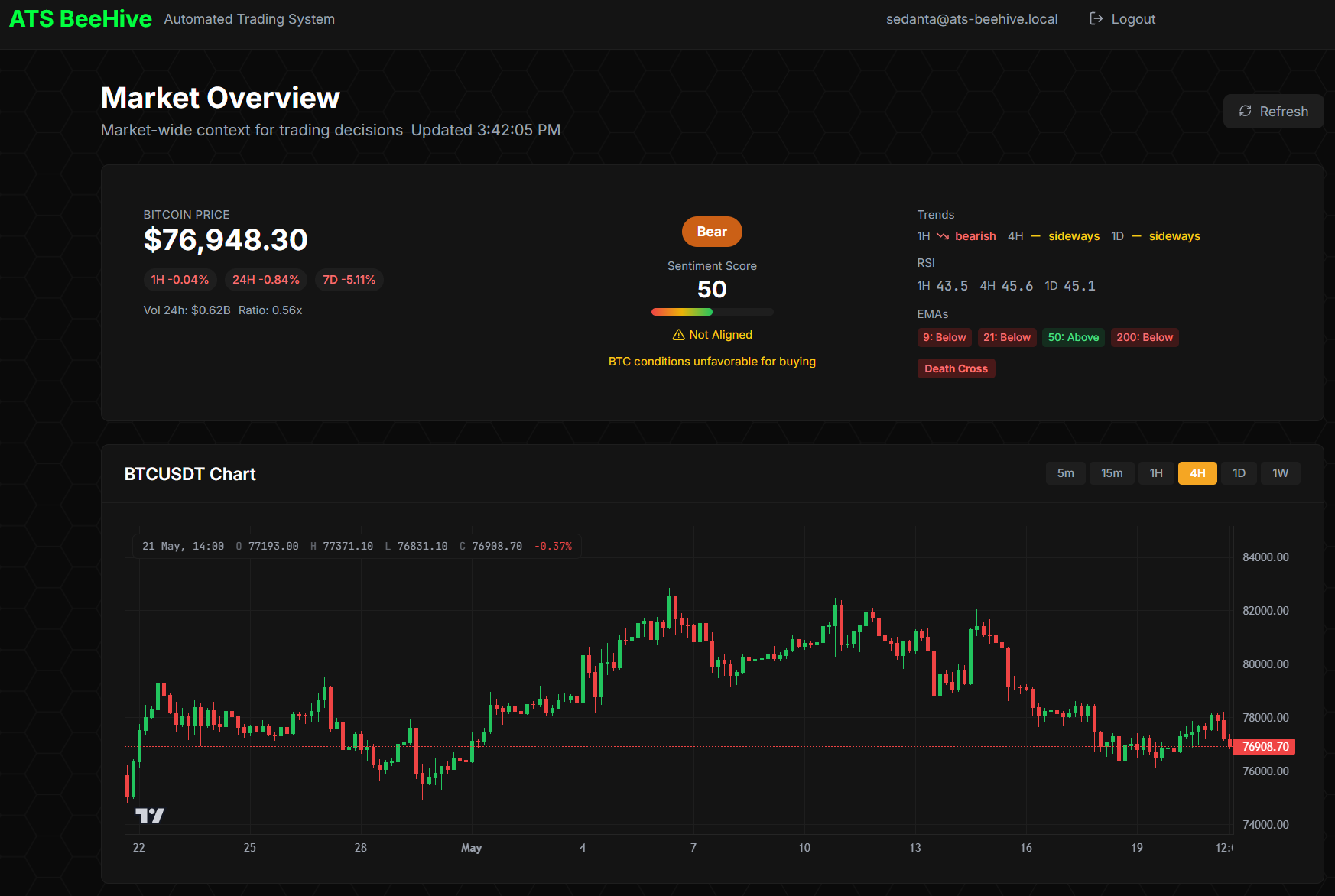
The regime determination itself lives in btc_market_state (current) plus an append-only btc_market_state_history (B01 / migration 144). The historical table makes backtests point-in-time correct — you can re-simulate a strategy against the regime as it was at that hour, not as it is now. That same append-only pattern shows up for strategy_configurations_history and system_settings_history (B03 / migration 146): every config change is effective-dated, so any historical decision can be re-evaluated against the config that was actually in effect.
Backtesting As Default Workflow
Every new strategy ships with a backtest before the first live trade. The backtest engine has its own schema (backtest_runs, backtest_trades, backtest_blocked_signals, backtest_equity_curve, backtest_comparisons, backtest_sweeps) and a UI in the dashboard.
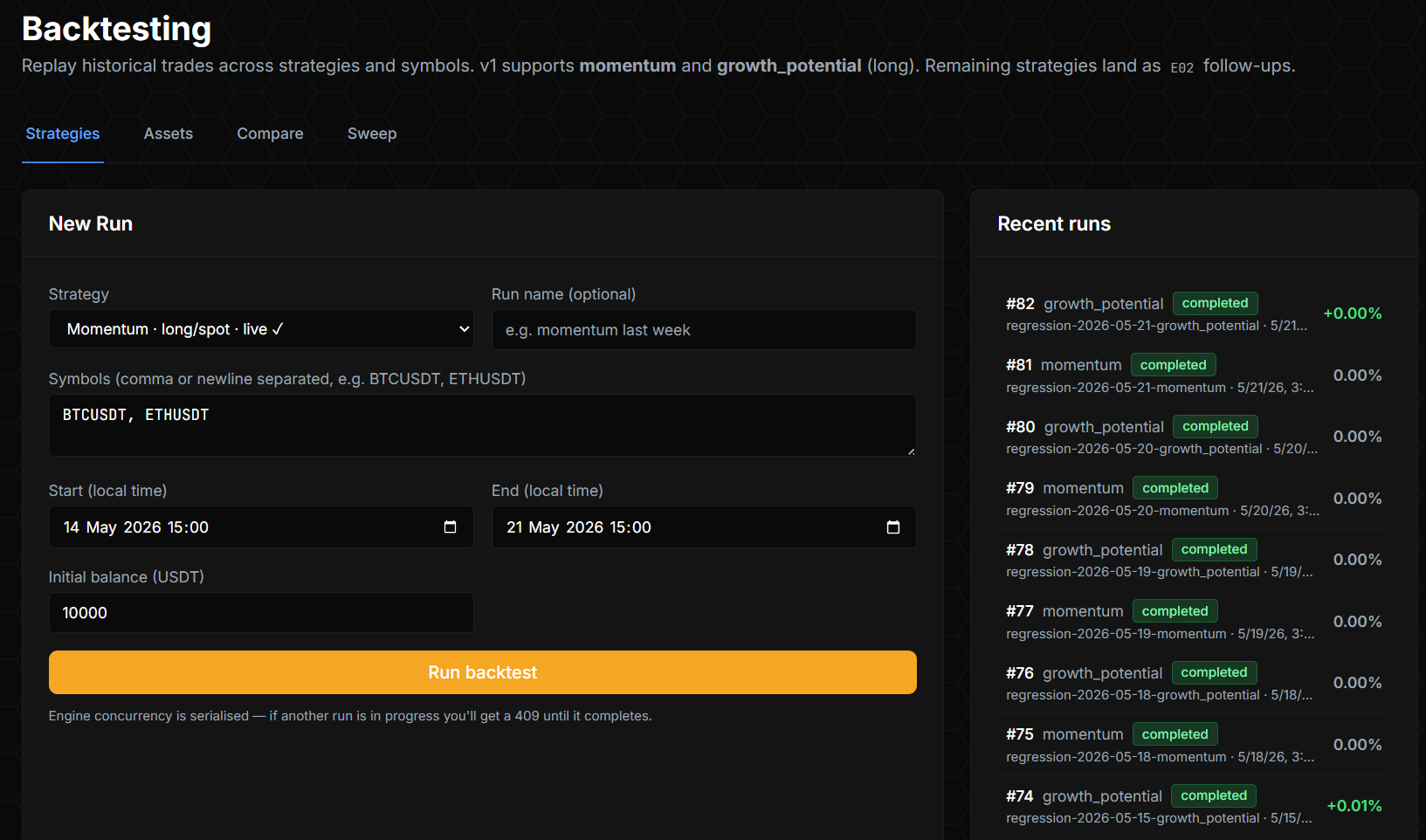
backtest_blocked_signals is the unique piece. It captures every signal the strategy would have generated but was blocked by a gate — wrong regime, position cap hit, microstructure failed, signal stale, cooldown active. The blocked-signals table is what makes a backtest debuggable, not just scorable. You can see what the strategy wanted to do, what stopped it, and decide whether the gate was right.
Engine concurrency is bounded: engine concurrency is serialized — if another run is in progress you'll get a 409 until it completes. This is a deliberate constraint — only one heavy compute run at a time on the shared infrastructure, to keep live trading latency predictable.
OHLCV Coverage as Observability
The trading system depends on a complete, accurate OHLCV history across symbols and timeframes. A gap in 4h candles for one symbol could silently distort a momentum signal. So coverage itself is a first-class observable.
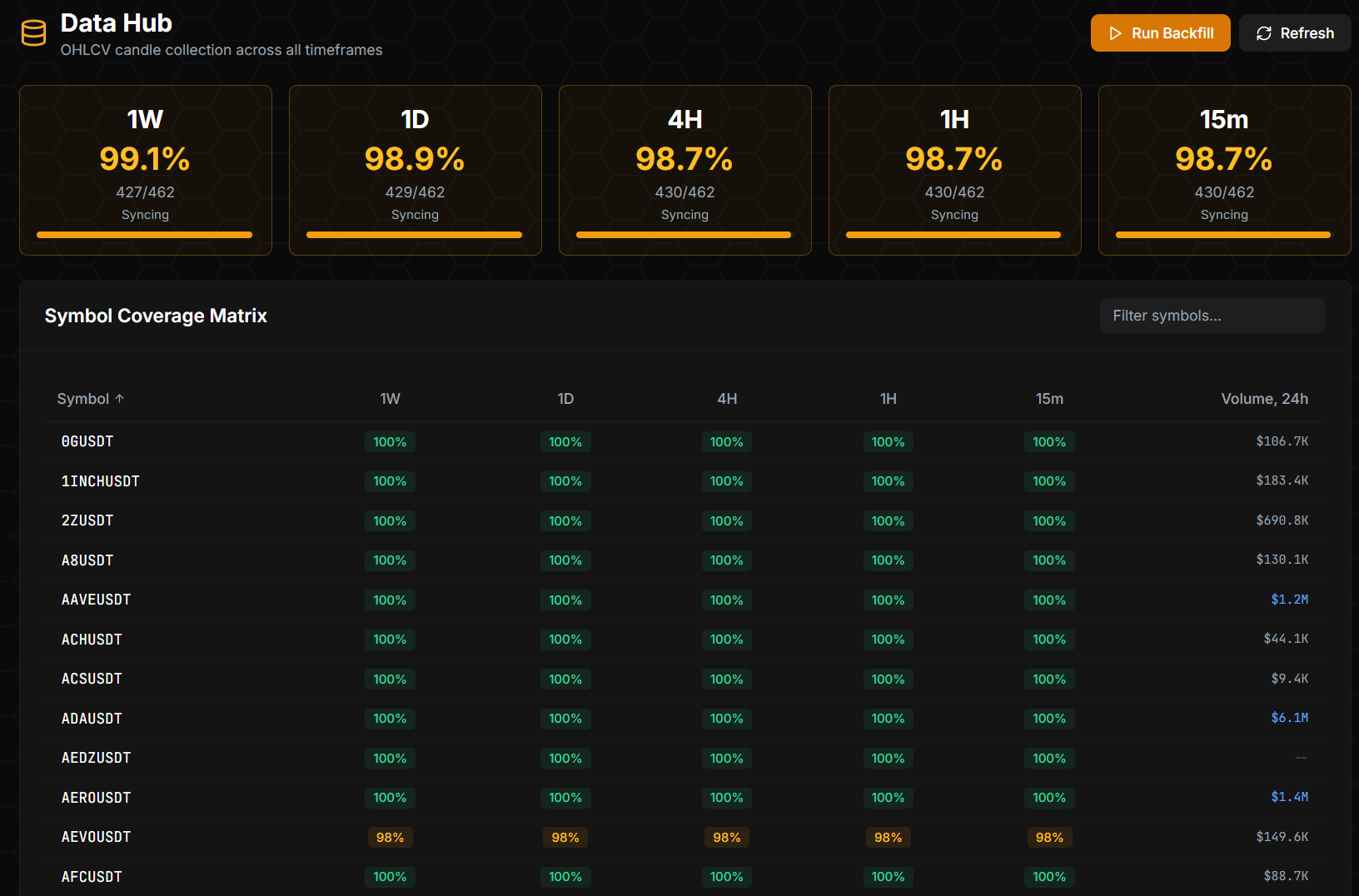
The Data Hub page exposes a per-symbol per-timeframe coverage grid. Greens mean the coverage is current; ambers/reds mean the symbol has gaps in that timeframe. A manual Run Backfill button lets me kick a backfill for a specific symbol/timeframe; an automated backfill loop also runs on a schedule.
This matters because observability for data quality is just as important as observability for service health. The system pages me about a missing OHLCV row before it pages me about a missed trade — because by the time the trade is missing, the data was bad hours ago.
The Live Trading View
The Assets view is where the trader looks for what the system is actually doing right now: portfolio value, today's P&L, 7-day P&L, 30-day P&L, 6-month P&L, all-time P&L, funding-account balance, unified-account balance, recent trades by symbol, current state per asset (Owned / Traded / Watched), wallet balance, current price, today's invested amount, manual Buy/Sell action buttons per row.
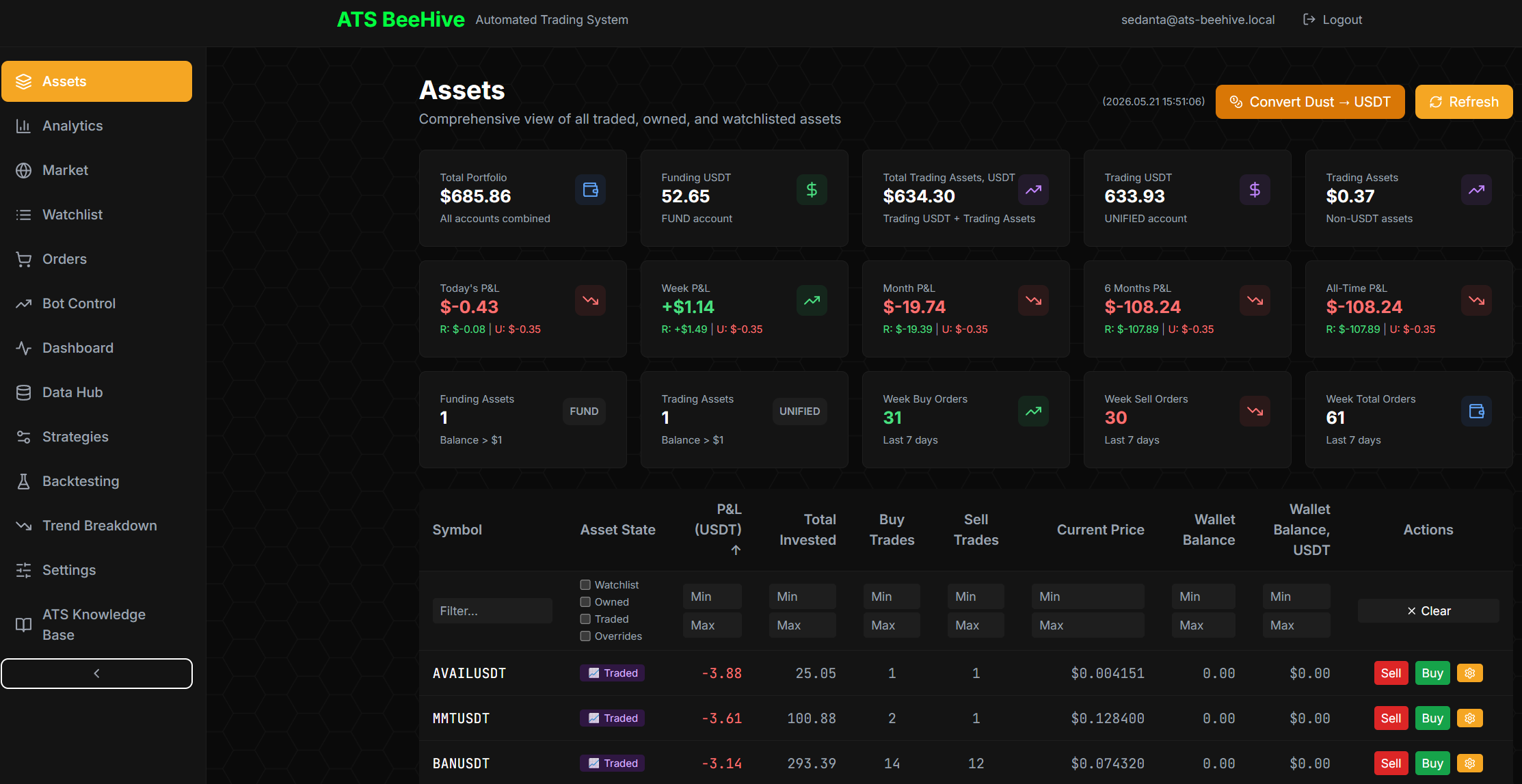
The dollar values shown are real but small — this system runs against a personal account, not on institutional capital. The point of running real money is that real WebSocket order placement, real fee accounting, real fill-or-kill semantics, and real slippage behavior are observable. A simulated environment doesn't teach you about those.
Analytics drills deeper. The Portfolio P&L chart (hourly) is anchored on the authoritative portfolio_hourly_snapshots table — never derived from wallet aggregates, per the documented anti-pattern. Below it, Trading Volume & Net P&L (hourly) shows buy volume, sell volume, fees, and the running cumulative net P&L curve.
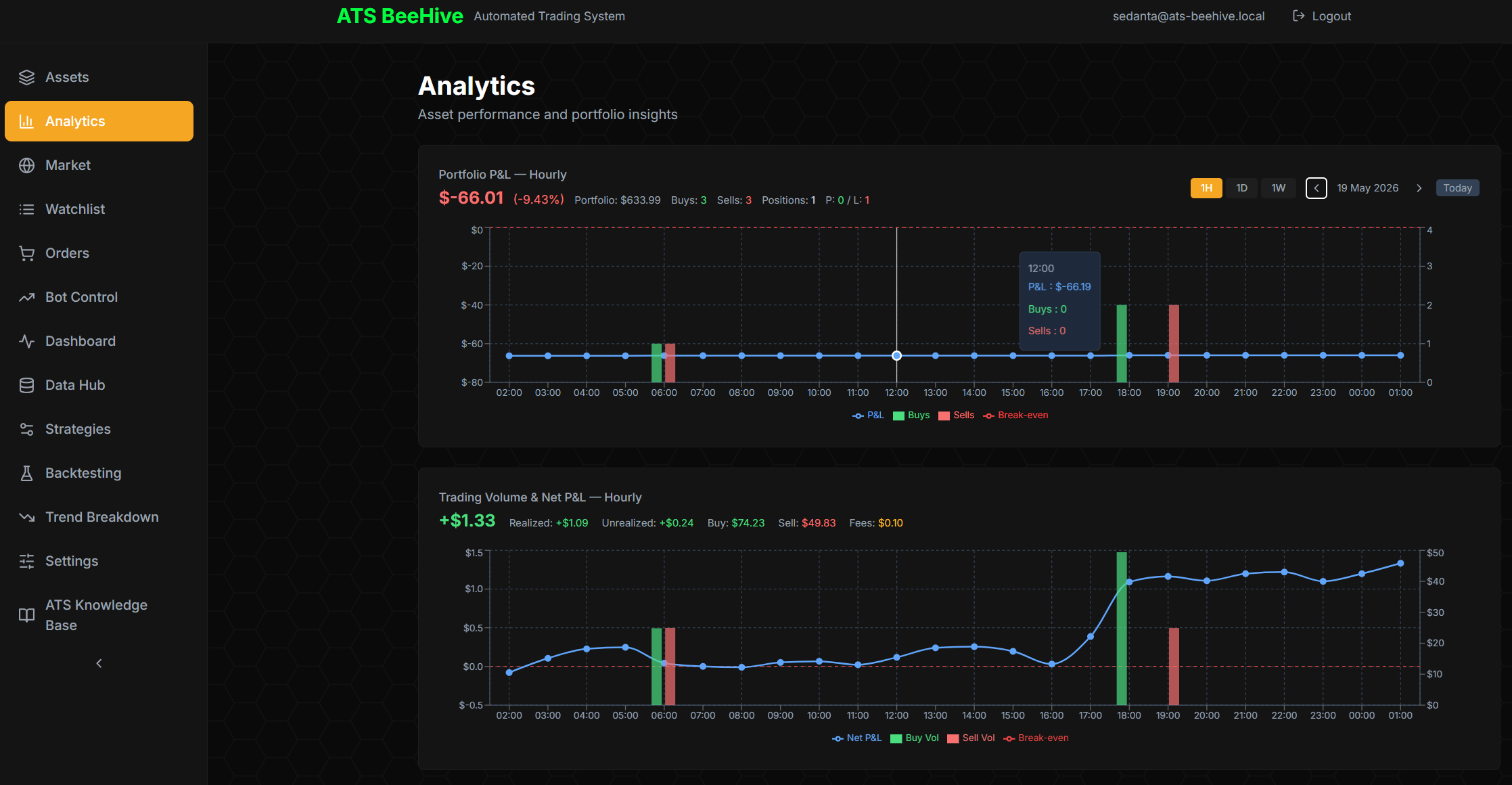
The forensic value of these charts isn't day-to-day P&L (the system is currently in modest drawdown). It's that every dot, bar, and line is reconcilable. The chart, the table, the audit log, the wallet — they all agree, because they all read from the same authoritative snapshot.
Three-Layer Forensics
When something goes wrong, the question is which log to read first. The codebase encodes the answer in CLAUDE.md as a small table:
| Layer | Where | Retention | When to use |
|---|---|---|---|
| Application logs (host volume) | services/<svc>/logs/<svc>.log |
30 × 100 MB (analytics) / 30 × 10 MB (api-gateway, trading-bot) | Logic, signal generation, order flow. Survives container recreates. |
| Docker container logs | docker compose logs <svc> --since=... |
30 × 100 MB rolling per service | First-pass triage, recent hours/days, startup errors. |
| Cron + one-shot run logs | /srv/ats-beehive/logs/cron/ and .claude-cron/<task>.log |
unbounded (manual rotation) | Output of scheduled claude --print runs. |
The non-obvious rule is in the application-logs row: for incidents older than ~24h, always start with the host-volume log file, not docker compose logs. Container logs are great for live tailing but the JSON driver caps mean older entries get rotated out. The host-volume logs survive container recreates and have a longer retention window.
That rule lives in docs because it took me re-discovering the gap twice before I wrote it down.
What This Has Taught Me About AI-Collaboration at Scale
The trading system is mostly not novel as software. It's a CRUD app over a market — fetch data, score signals, execute orders, audit results, repeat. There are thousands of trading systems with this rough shape.
What's novel is what running it through Claude Code as the primary IDE since November 2025 has forced into existence:
-
Plans are the most important artifact. The plan files in
plans/are the soul of the project. The code is downstream of them. Read the plans first when you're trying to understand any decision. -
Documentation has to be agent-maintained, or it lies. The 151-article knowledge base survives because an agent rebuilds it from source on MD5 drift. Without that, every article would be subtly wrong inside a quarter.
-
Agents work better when they have narrow, named roles.
investigate-agentdoes forensics.git-workflow-agentdoes commits.knowledge-base-agentdoes docs. They don't overlap. They don't pretend to be general-purpose. Each one is a function call with a defined contract. -
Slash commands are the daily UI. I don't type prompts. I run
/ats-health-check,/weekly-report,/investigate AVAXUSDT 2026-05-20. The skill markdown file is the user interface to the agent fleet. -
Anti-patterns must live in docs the next session reads. Forensic context from production incidents has to land in
CLAUDE.mdor it gets re-discovered. The P&L double-count and the running-cumulative trap are warnings the agent inherits forever now. -
Deferred work runs locally, never remotely. Local systemd timers + crontab +
claude --printsurvive reboots and inherit the full env. The harness's/scheduleskill launches remote agents that can't reach the DB. This isn't a Claude Code limitation; it's a topology constraint that the project rules acknowledge. -
MCP servers are the connective tissue. Postgres RW (
mcp__postgres__query), filesystem, memory (knowledge graph across sessions), sequential-thinking, qmd (BM25+vector docs search), GitHub. The agent fleet uses these as primitives. Without them, every session would re-fetch every fact. -
Single source of truth, in the database, not in code. Strategy parameters, system settings, BTC regime — all live in tables with append-only history. Configuration is data, not source. Restart-safe and re-simulatable.
-
Soak periods before activation. Every new strategy gets a watchlist-only soak first, observed via the live-monitor daemon, before its buy gate flips. Every new automation gets the same.
-
The discipline is the product. The trading itself is not the point. The system's value as a portfolio artifact is the engineering discipline that makes AI-assisted dev at this scale coherent. If I had to choose between trading edge and the discipline, I'd keep the discipline.
That last point is the one I want anyone reading this to take away. The Automated Trading System sits at the top of this portfolio not because it makes money (it doesn't, materially — the markets are hard, and even with discipline this is a small system competing in a brutal arena). It's at the top because it's the most complete demonstration of what AI-human collaboration looks like when it has to be right, repeatedly, at production scale, across hundreds of plan-first iterations.
Everything else in the portfolio is a smaller version of the same lessons.